MACH Booster Inventory Service by Aries Solutions
Purpose of the solution
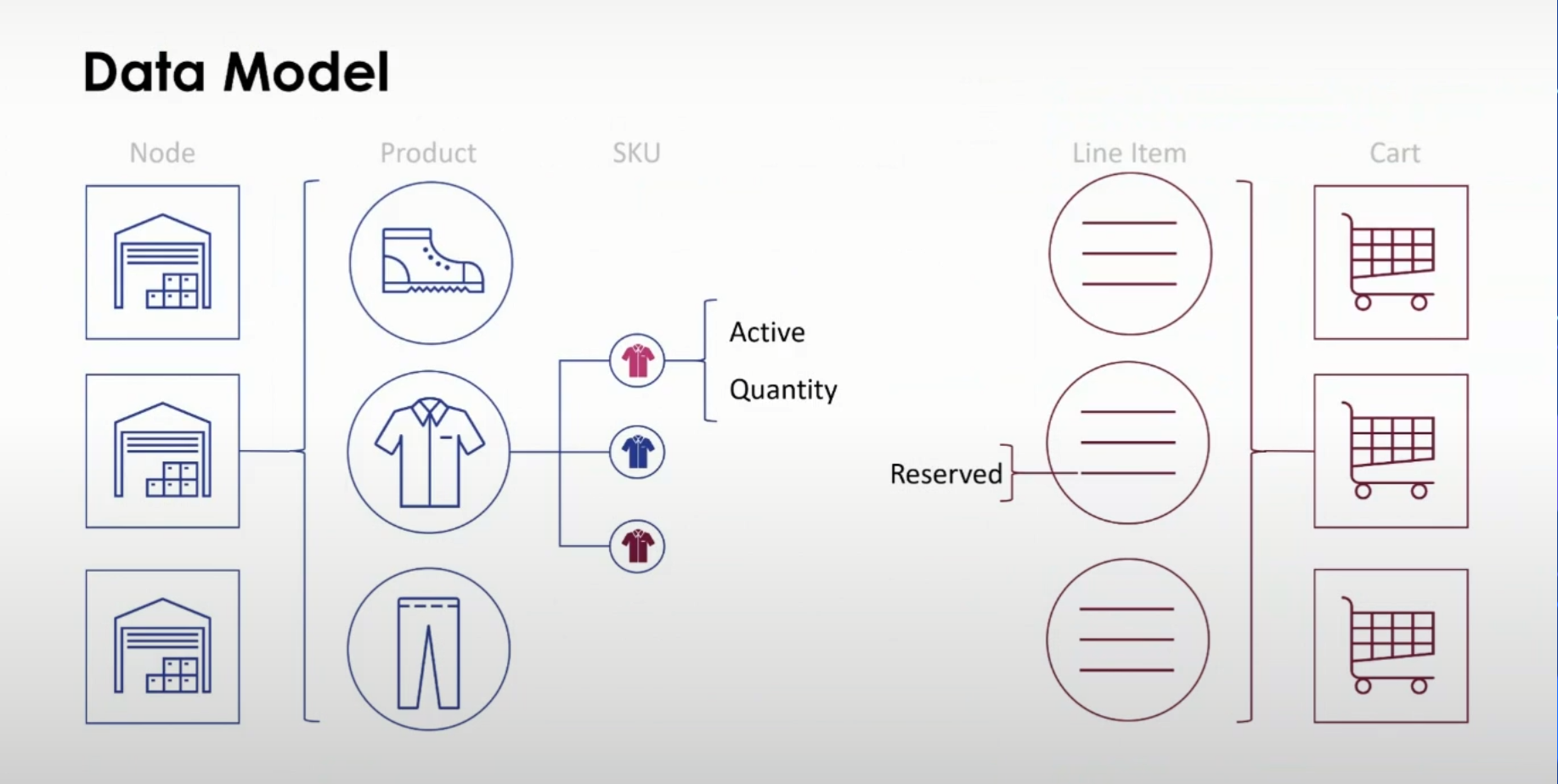
This project is a microservice designed for managing inventory in high-throughput environments. Unlike traditional warehouse inventory systems that include complex logistics and inventory balancing features, this service focuses on maintaining a streamlined dataset to track availability across different inventory locations (referred to as Nodes within the industry). The primary aim is to support online experiences, where rapid and numerous API calls are expected. The inventory availability is dynamically updated to reflect online sales and stock refreshes from physical stores as they happen.
Composition of the Accelerator
Database: Google Cloud Platform Cloud Spanner Backend: JDK 17 Build Tool: Maven Containerization: Docker Hosting: k8s
Benefits of the solution
High-Throughput Handling: Optimized for environments with a high number of API calls.
Dynamic Inventory Tracking: Real-time updates on inventory availability, taking into account both online sales and physical store refreshes.
Scalable Architecture: Leveraging GCP Cloud Spanner for unlimited scalability and relational semantics.
Containerized Deployment: Ready for Kubernetes with Docker, ensuring easy scaling and management.
Data Model